
科技
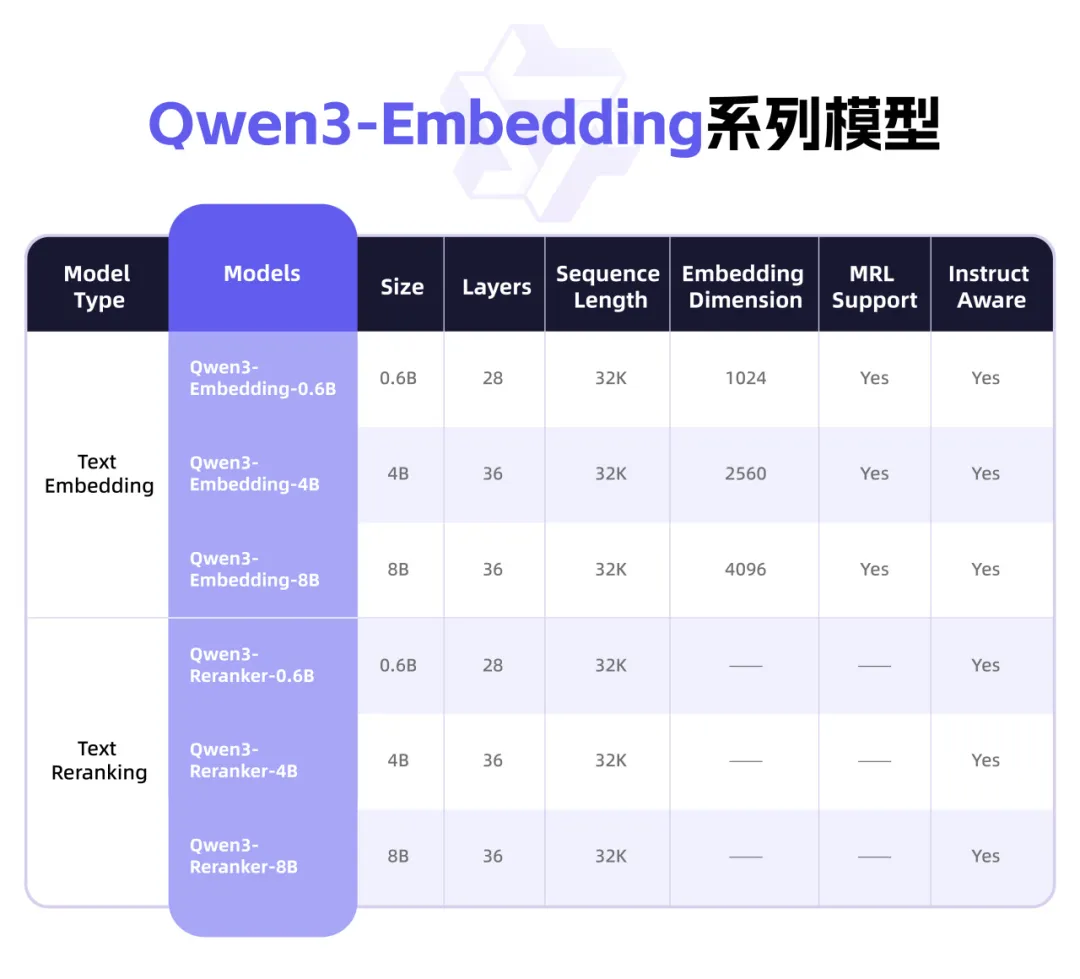
Qwen3-Embedding 系列模型
向量模型像是AI的“翻译器”,它可以将文本、图片等人类可认知的非结构化信息,映射到机器更易理解的向量空间,再基于这些向量实现高效的信息分类、检索或排序。也正因此,向量模型对于提升AI的语义理解、信息检索、多模态融合等核心能力至关重要。基于千问3模型,通义团队通过对比训练、SFT、模型融合等方法,打造出全新的千问3向量模型,包含文本嵌入模型 Qwen3-Embedding以及文本排序模型Qwen3-Reranker。
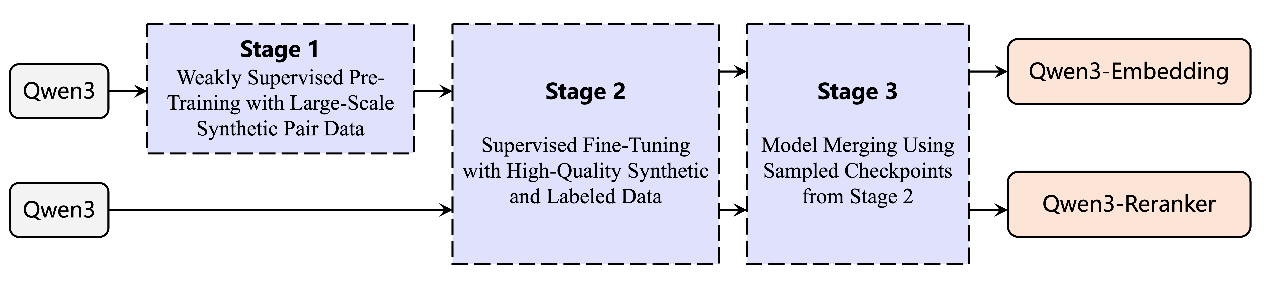
千问3向量模型系列训练过程图
相较于上一个版本,千问3向量模型在文本检索、聚类、分类等核心任务上提升最高40%以上的性能。同时,得益于千问3的多语言能力,千问3向量模型系列率先支持超100种语言,并涵盖多种编程语言,可实现强大的多语言、跨语言及代码检索能力。
为方便开发者,此次有9款千问3向量模型开源,涵盖0.6B、4B、8B等不同尺寸及GGUF版本。开发者可从中找到最符合需求的模型,自由组合模块,还可自定义向量或指令,实现特定任务、语言和场景的深度优化。比如,开发者可在智能搜索、推荐系统中采用Qwen3-Embedding作文本向量化,或者在RAG实践中用Qwen3-Reranker提升最终结果的相关性和准确性,甚至与视觉理解模型结合,探索前沿的跨模态语义理解。
目前,千问3 Embedding和Reranker模型均已在魔搭社区、Hugging Face和GitHub等平台上开源,开发者也可直接通过阿里云百炼使用API服务。
◆ 遵守中华人民共和国有关法律、法规,遵守《互联网新闻信息服务管理规定》。
◆ 尊重网上道德,承担一切因您的行为而直接或间接引起的法律责任。
◆ 您在宁夏财经网发表的言论,我们有权在网站内转载或引用。
版权与免责声明:
1 本网注明“来源:×××”(非宁夏财经网)的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,本网不承担此类稿件侵权行为的连带责任。
2 在本网的新闻页面或BBS上进行跟帖或发表言论者,文责自负。
3 相关信息并未经过本网站证实,不对您构成任何投资建议,据此操作,风险自担。
4 如涉及作品内容、版权等其它问题,请在30日内同本网联系。
广告热线:


